強化学習を用いた冷媒回路の制御に関する研究
研究背景、概要、目的
近年のEVシフトに伴い、車両のモデル化によるシステム設計や電費改善が重要視されている。
冷媒回路は膨張弁で制御されるが、物理変数が多く最適化が困難なため、機械学習の活用が求められる。しかし、
膨大な変数の調整には時間がかかり、十分なデータも存在しない。本研究では、オンライン強化学習を用いた膨張弁
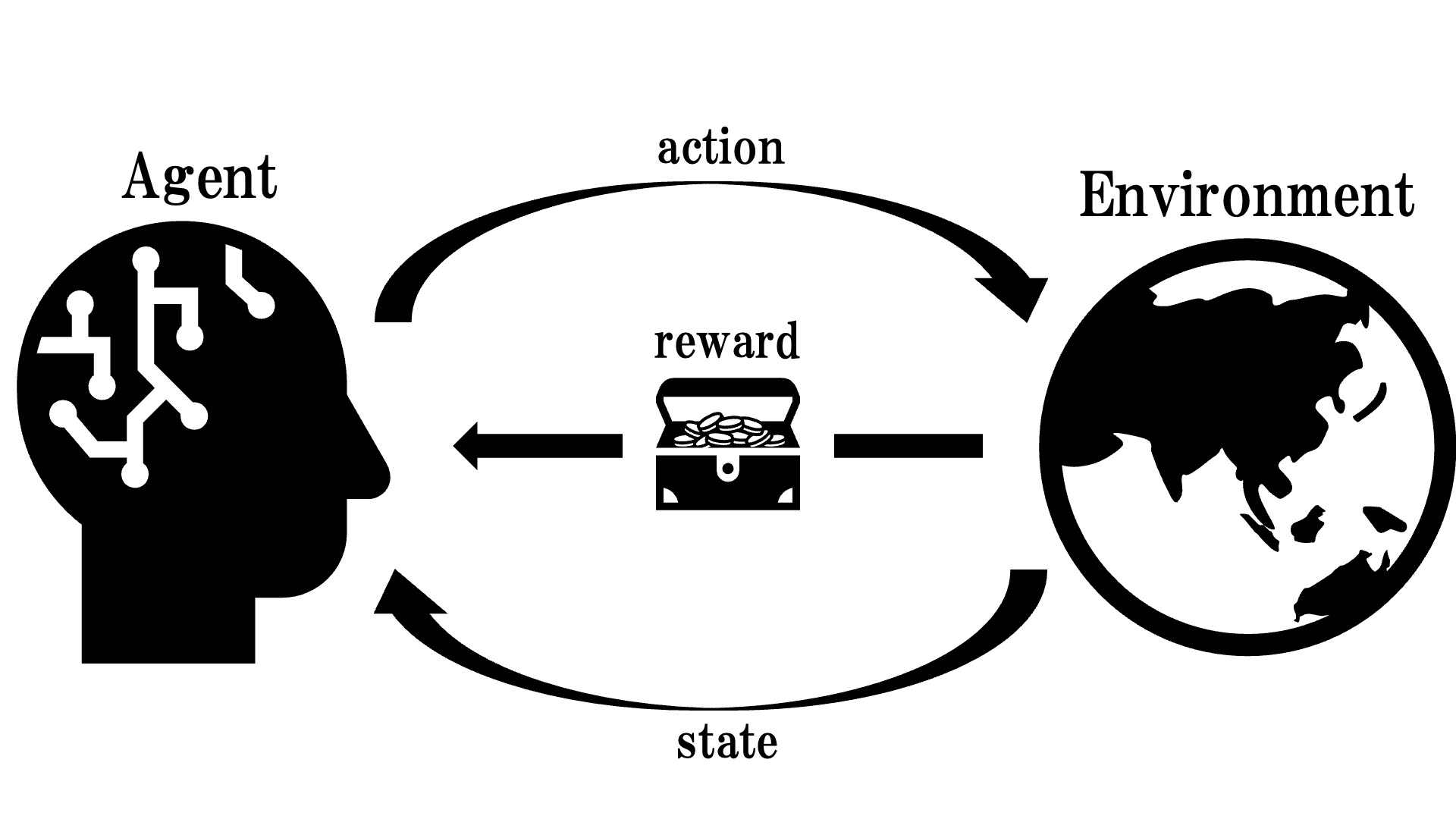
の最適制御を目的とする。強化学習は、エージェントが環境から報酬を得ながら最適行動を学習する手法である。
特にSoft Actor-Critic (SAC) は、報酬関数にエントロピー項を加え、探索と報酬のバランスを最適化するアルゴリズムであり、
本研究の冷媒回路制御への応用が期待される。
参考文献
・Pieter Abbeel Sergey Levine Tuomas Haarnoja, Aurick Zhou. Soft actor-critic: Off-policy maxi-
・mum entropy deep reinforcement learning with a stochastic actor. arXiv:1801.01290, 2018.